The relationship between the expected response and the explanatory variable is a straight line.
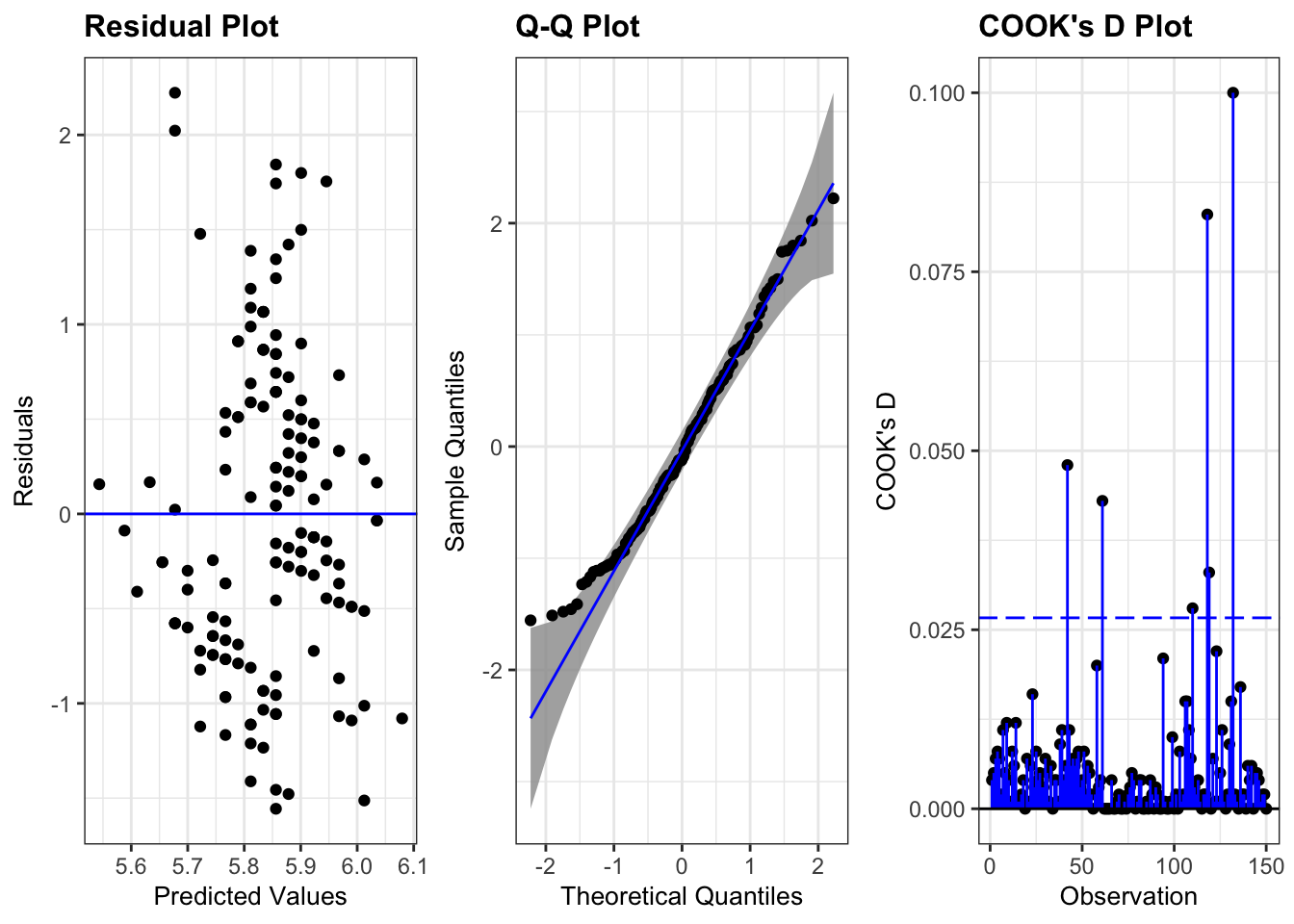
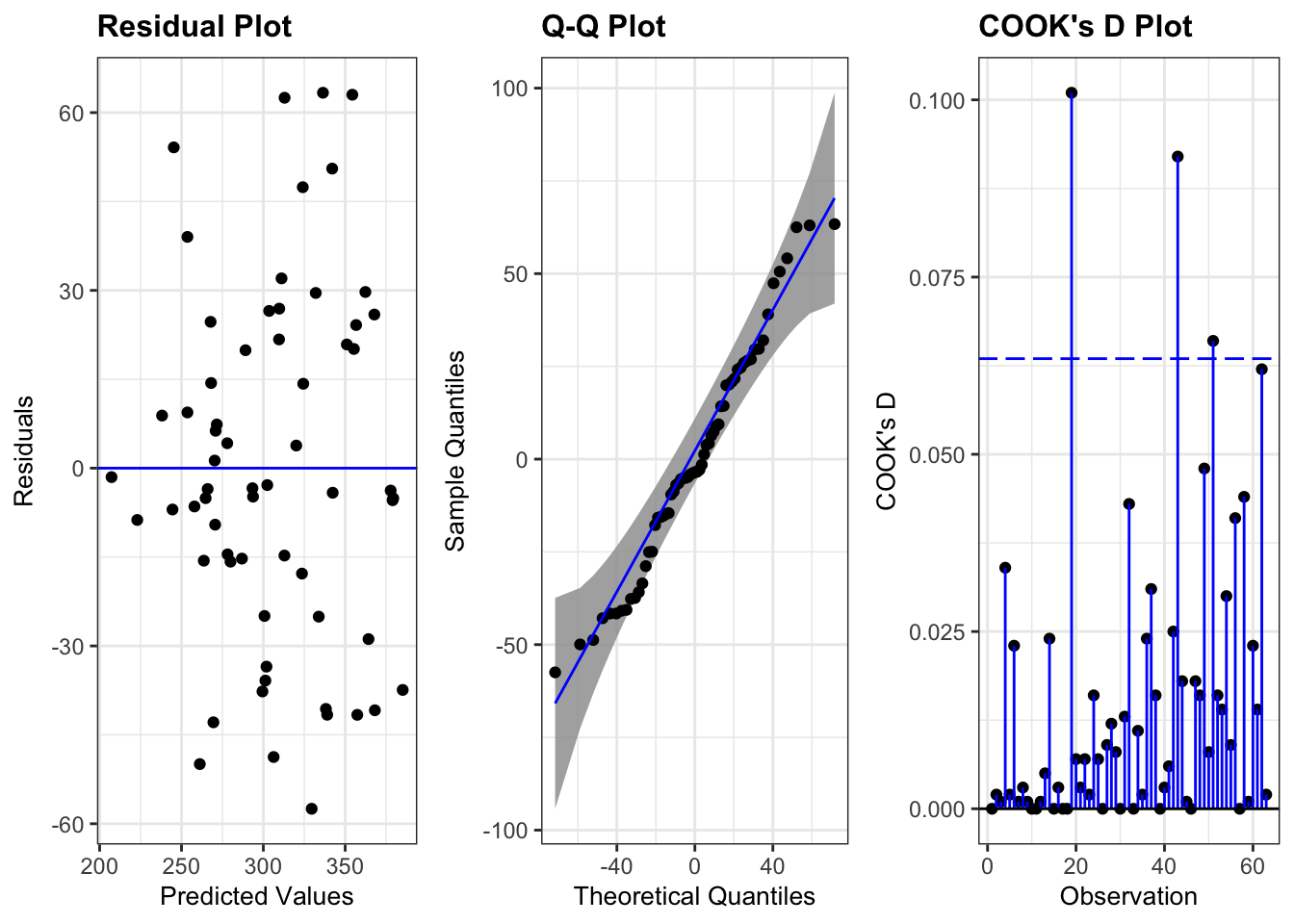
3.1.4 Diagnostics
m <-lm(Sepal.Length ~ Sepal.Width, data = iris)ggResidpanel::resid_panel(m, plots =c("resid", "qq", "cookd"), qqbands =TRUE, nrow =1)
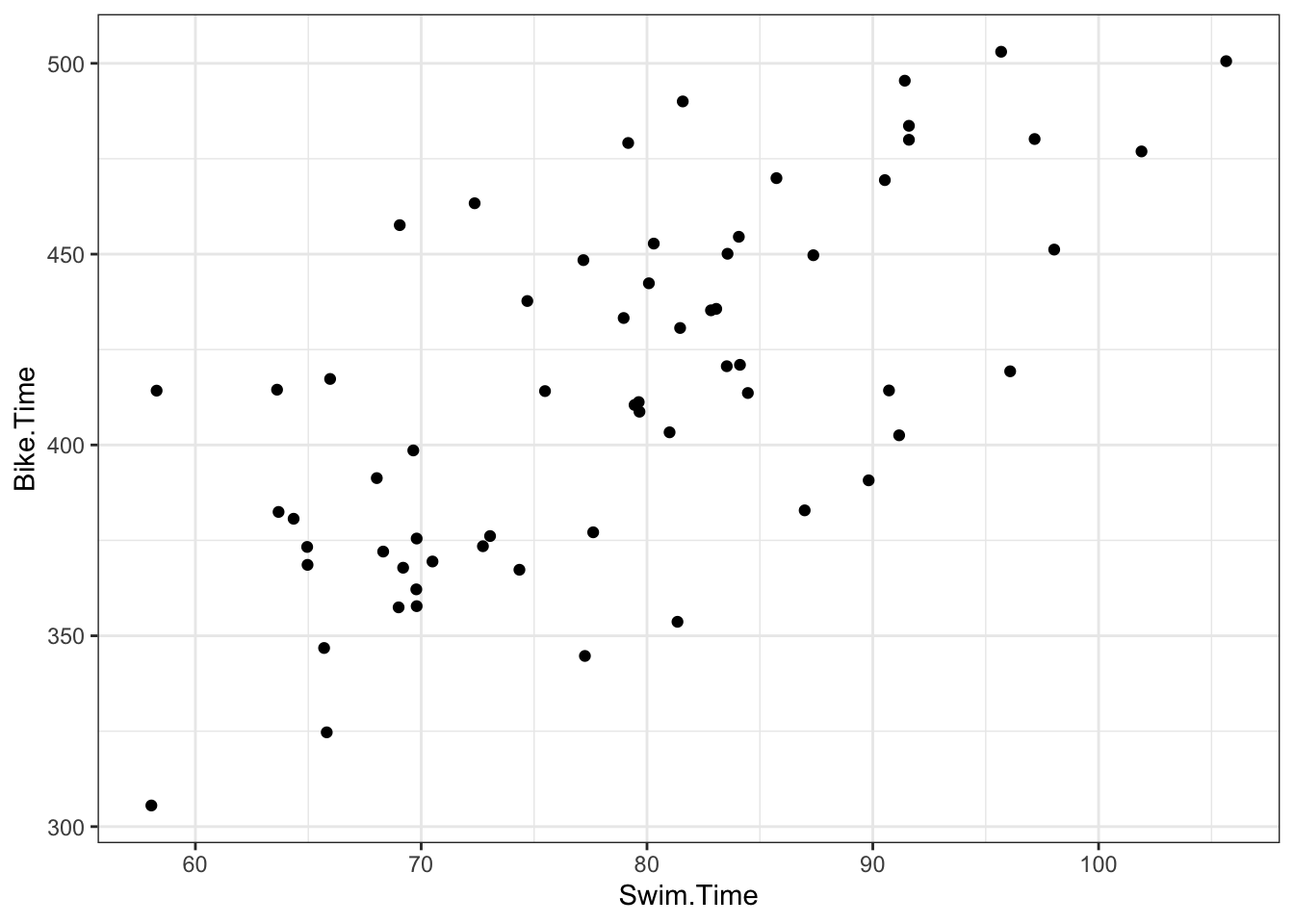
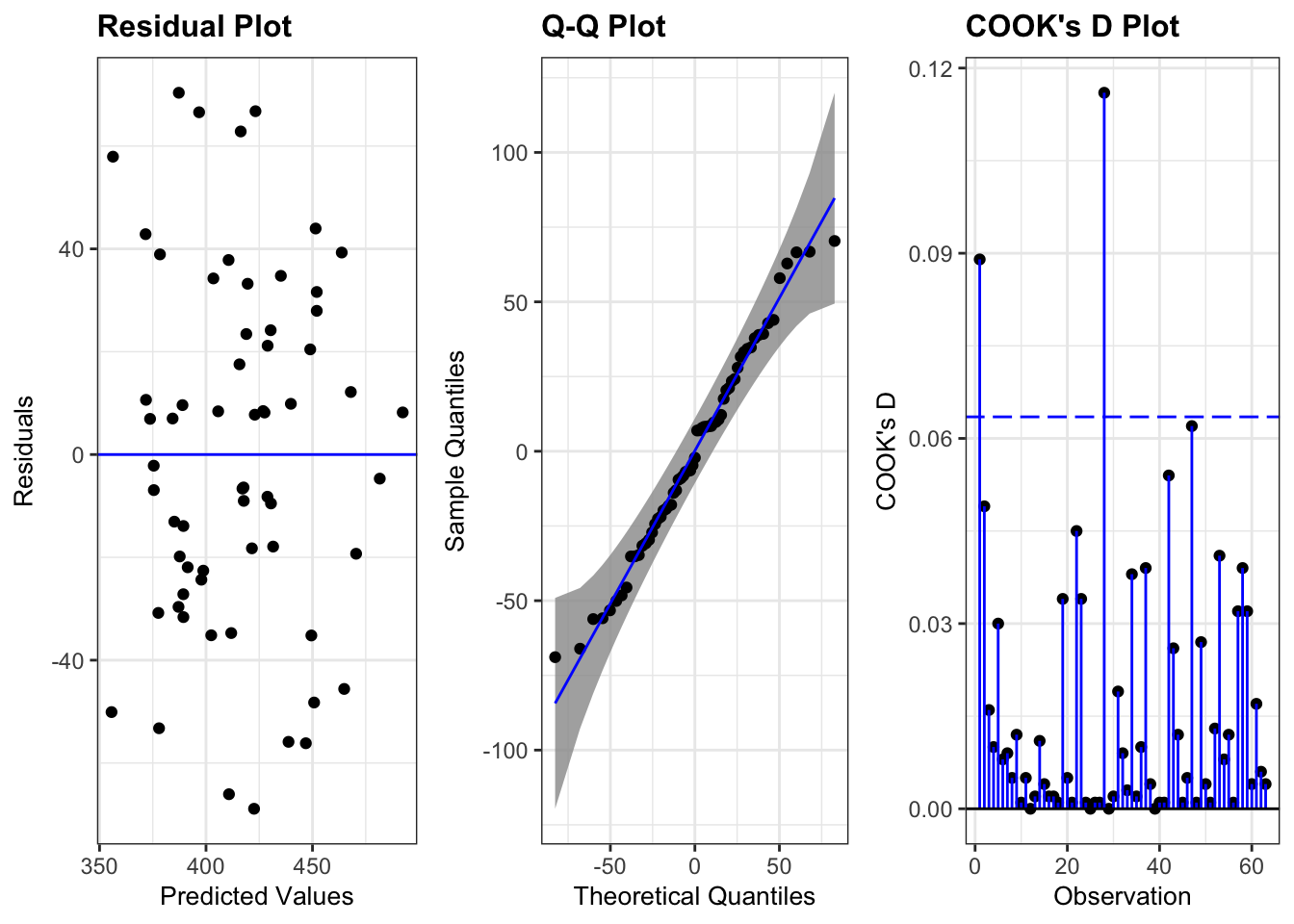
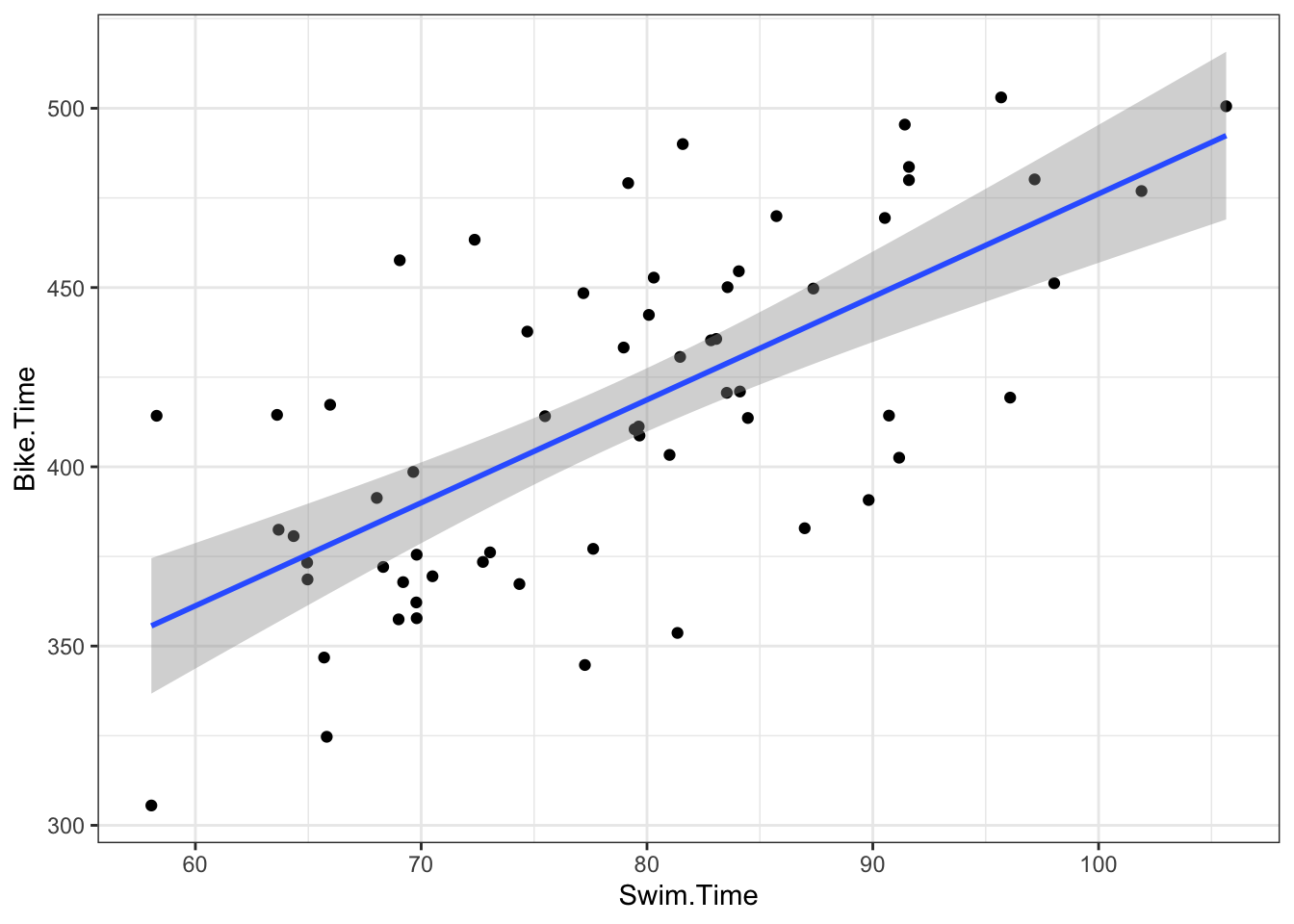
3.1.5 Triathlon Data
d <-read_csv("data/ironman_lake_placid_female_2022_canadian.csv")
Rows: 64 Columns: 17
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (6): Name, Country, Gender, Division, Finish.Status, Location
dbl (11): Bib, Division.Rank, Overall.Time, Overall.Rank, Swim.Time, Swim.Ra...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
When swim time is 0, the expected Bike Time is 189 mins with a 95% interval of (125, 253). For additional minute of swim time, the bike time is expected to increase 2.9 mins
(2.1, 3.7). The model explains 45% of the variability in bike time.
Note that \[
Y_i \stackrel{ind}{\sim} N(\mu_{g[i]}, \sigma^2)
\] where \(g[i] \in \{1,2\}\) determines the group membership for observation \(i\)
is equivalent to \[
Y_i \stackrel{ind}{\sim} N(\beta_0 + \beta_1 \mathrm{I}(g[i] = 2), \sigma^2)
\] where \(\mathrm{I}(g[i] = 2)\) is the indicator function, i.e. \[
I(A) = \left\{
\begin{array}{ll}
1 & A\mbox{ is TRUE} \\
0 & \mbox{otherwise}
\end{array}
\right.
\] % i.e. \(I(A) = 1\) if \(A\) is true and \(I(A) = 0\) otherwise,
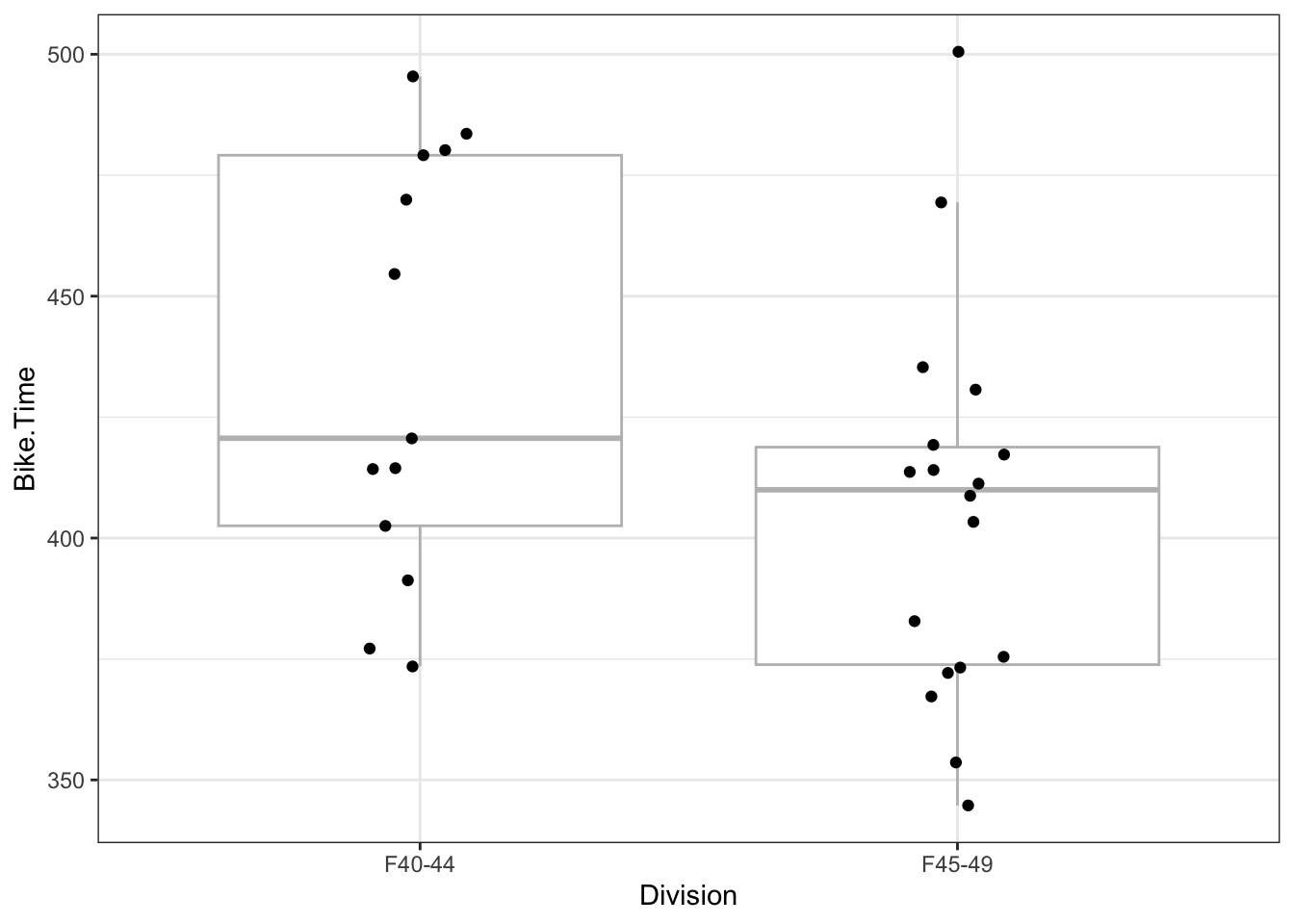
Two Sample t-test
data: Bike.Time by Division
t = 1.9964, df = 29, p-value = 0.05535
alternative hypothesis: true difference in means between group F40-44 and group F45-49 is not equal to 0
95 percent confidence interval:
-0.7329461 60.6715501
sample estimates:
mean in group F40-44 mean in group F45-49
435.1295 405.1602
3.2 Multiple Linear Regression
3.2.1 Model
For observation \(i = \{1,2,\ldots,n \}\), let
\(Y_i\) be the value of the response variable and
\(X_{i,j}\) be value of the \(j\)th explanatory variable
\(\beta_0\) is the expected response when all \(X_{i,j} = 0\)
\(\beta_j\) is the expected increase in the response when \(X_{i,j}\) is increased by 1 and all other explanatory variables are held constant
When multiple regression is used, you will often see people write the phrases after controlling for'' orafter adjusting for’’ followed by a list of the other explanatory variables in the model.
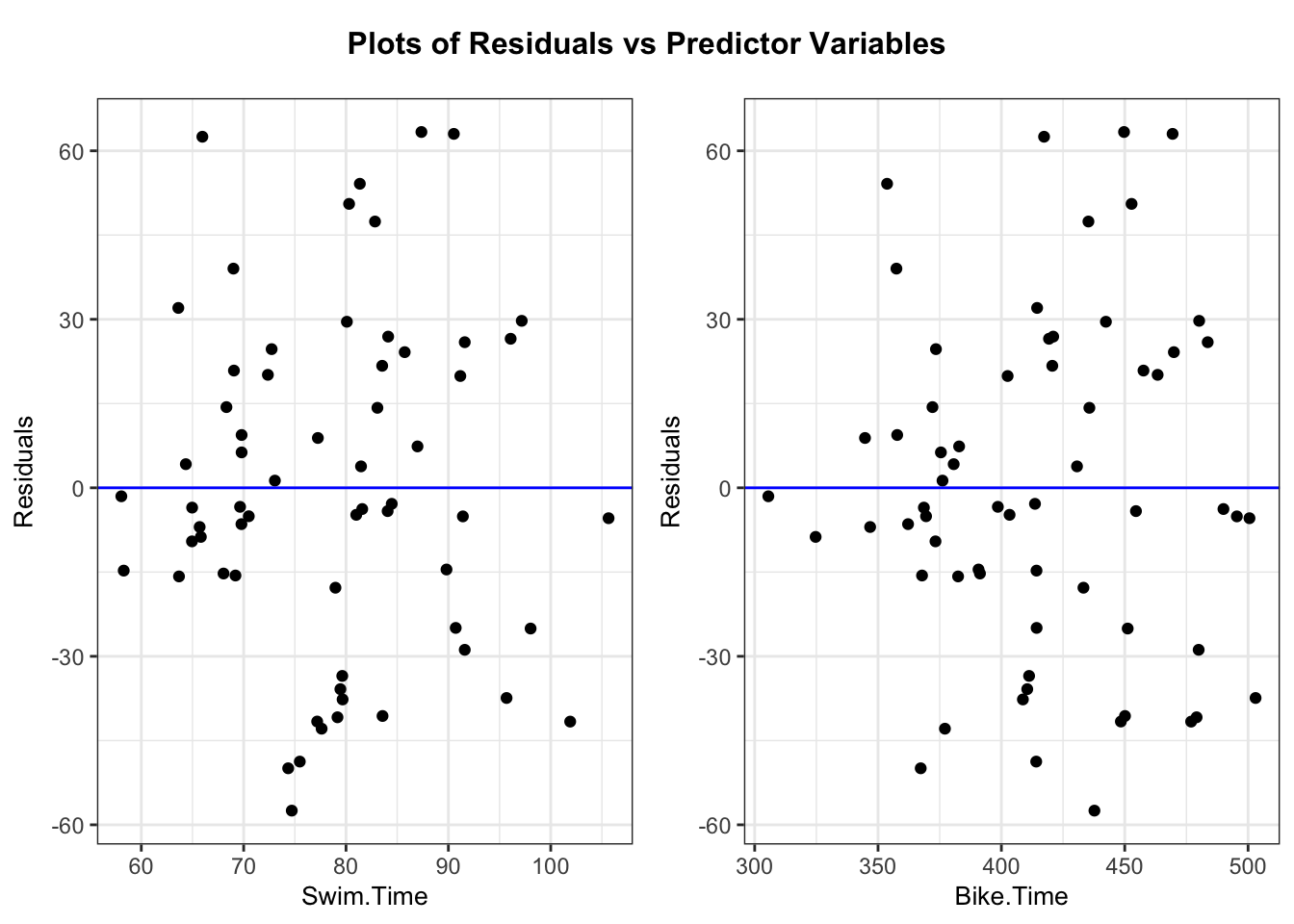
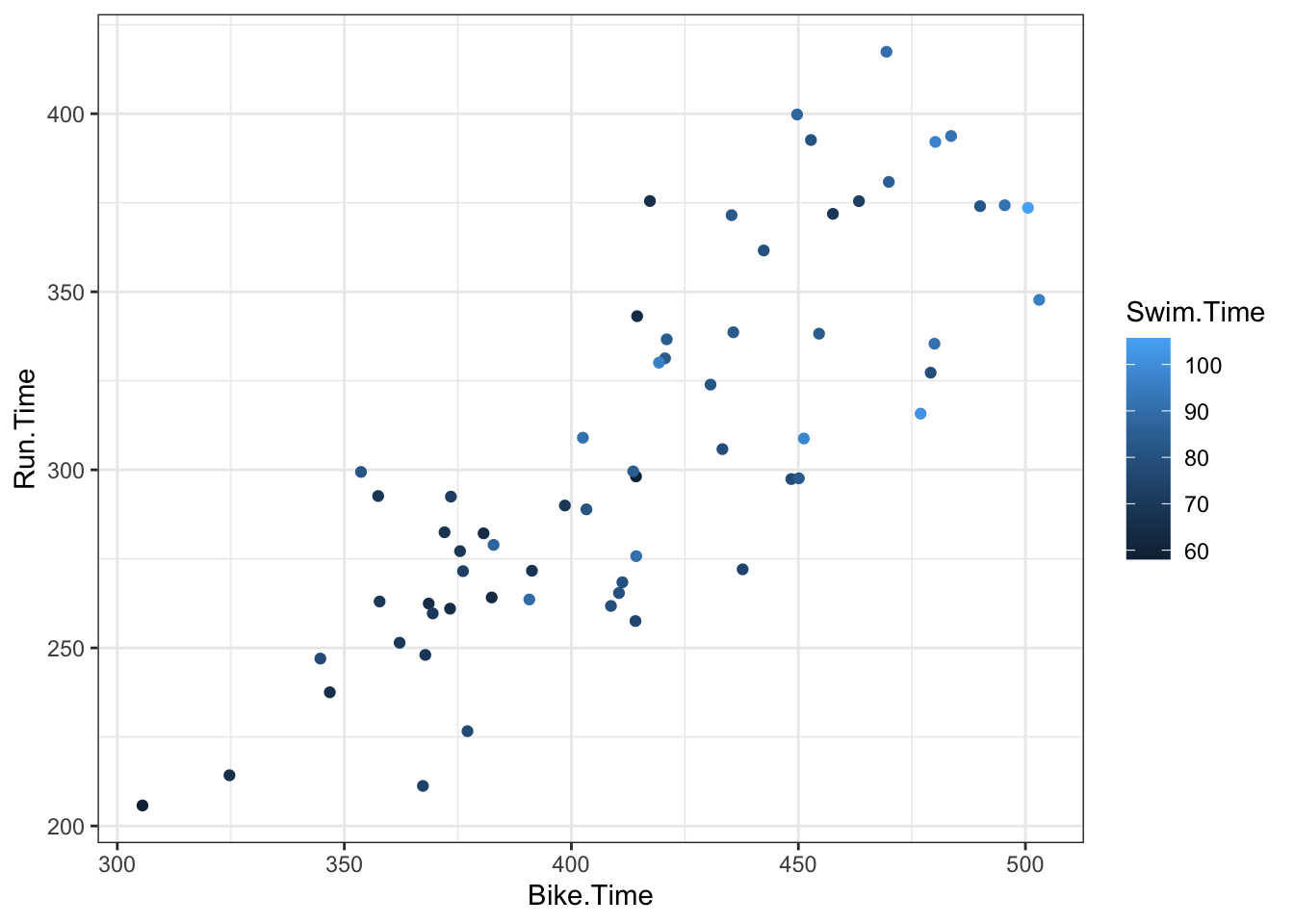
Using the 2022 Women’s Lake Placid Ironman data, we fit a regression model using run time as the response variable and swim and bike times as the explanatory variables. After adjusting for bike time, each minute increase of swim time was associated with a -0.38 minute increase in run time with a 95% interval of (-1.33, 0.58). After adjusting for swim time, each minute increase of bike time was associated with a 0.97 (0.75, 1.2) minute increase in run time. The model with swim and bike time accounted for 67% of the variability in run time.
3.3 ANOVA
When our explanatory variable is categorical with more than 2 levels, we can fit a regression model that will often be referred to as an ANOVA model.
To fit this model, we do the following
Choose one level to be the reference level (by default R will choose the level that comes first alphabetically)
Create indicator variables for all the other levels, i.e. \[
\mathrm{I}(\mbox{level for observation $i$ is $<$level$>$}) = \left\{
\begin{array}{ll}
1 & \mbox{if level for observation $i$ is $<$level$>$} \\
0 & \mbox{otherwise}
\end{array} \right.
\]
Fit a regression model using these indicators.
Most statistical software will perform these actions for you, but it is useful to know this is what is happening.
Summary statistics
d |>group_by(Division) |>summarize(n =n(),mean =mean(Run.Time),sd =sd(Run.Time) )
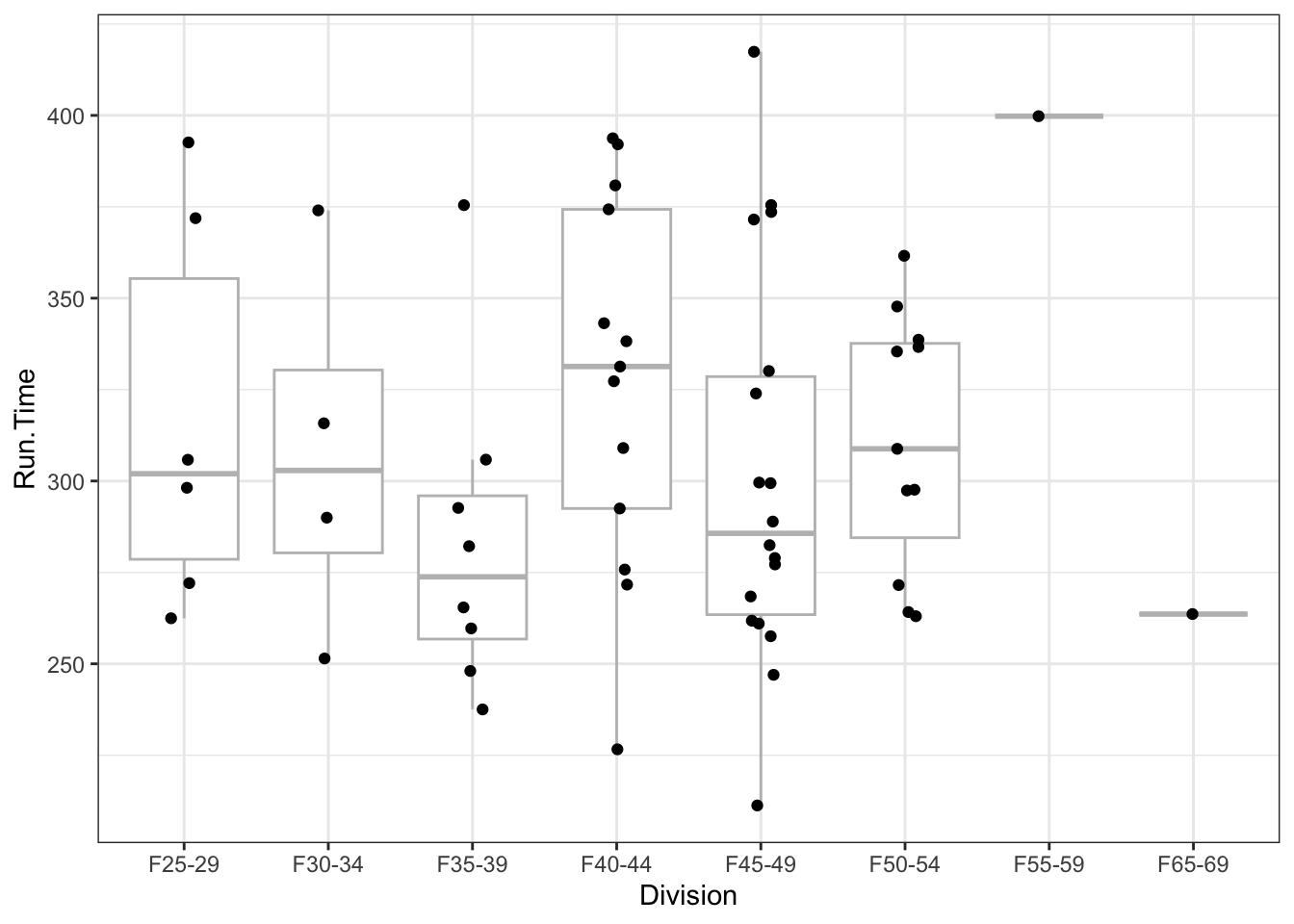
Using the 2022 Women’s Lake Placid Ironman data, we fit a regression model using run time as the response variable and age division as the explanatory variable. The mean run time for the F25-29 division was 5.3 hours with a 95% interval of (4.6, 6). There is evidence of a difference in mean run time amongst the divisions (ANOVA F-test p=0.27). The estimated difference in run time for the F25-29 division minus the F35-39 division was 34 (-19, 87) minutes. The model with division accounted for 14% of the variability in run time.