When sports allow ties, the statistical model used should accommodate the ordinal nature of the data. Namely, \[ \mbox{Win} > \mbox{Tie} > \mbox{Loss} \] We can extend the win-loss logistic regression model to accommodate the possibility of a Tie.
8.1 Model
To construct an ordinal logistic regression model, we will start with a latent-variable representation of the logistic regression model. We will then add additional cut-points to represent the different possible game outcomes.
8.1.1 Latent Variable Logistic Regression
Recall that our win-loss logistic regression model is \[H_g\stackrel{ind}{\sim} Ber(\pi_g) \quad \mbox{logit}(\pi_g)
= \zeta + \theta_{H[g]} - \theta_{A[g]}\] where
\(H_g\) is an indicator that the home team won game \(g\) (0 if home team lost, 1 if home team won),
\(\zeta\) is the home advantage, and
\(\theta_t\) is the strength of team \(t\).
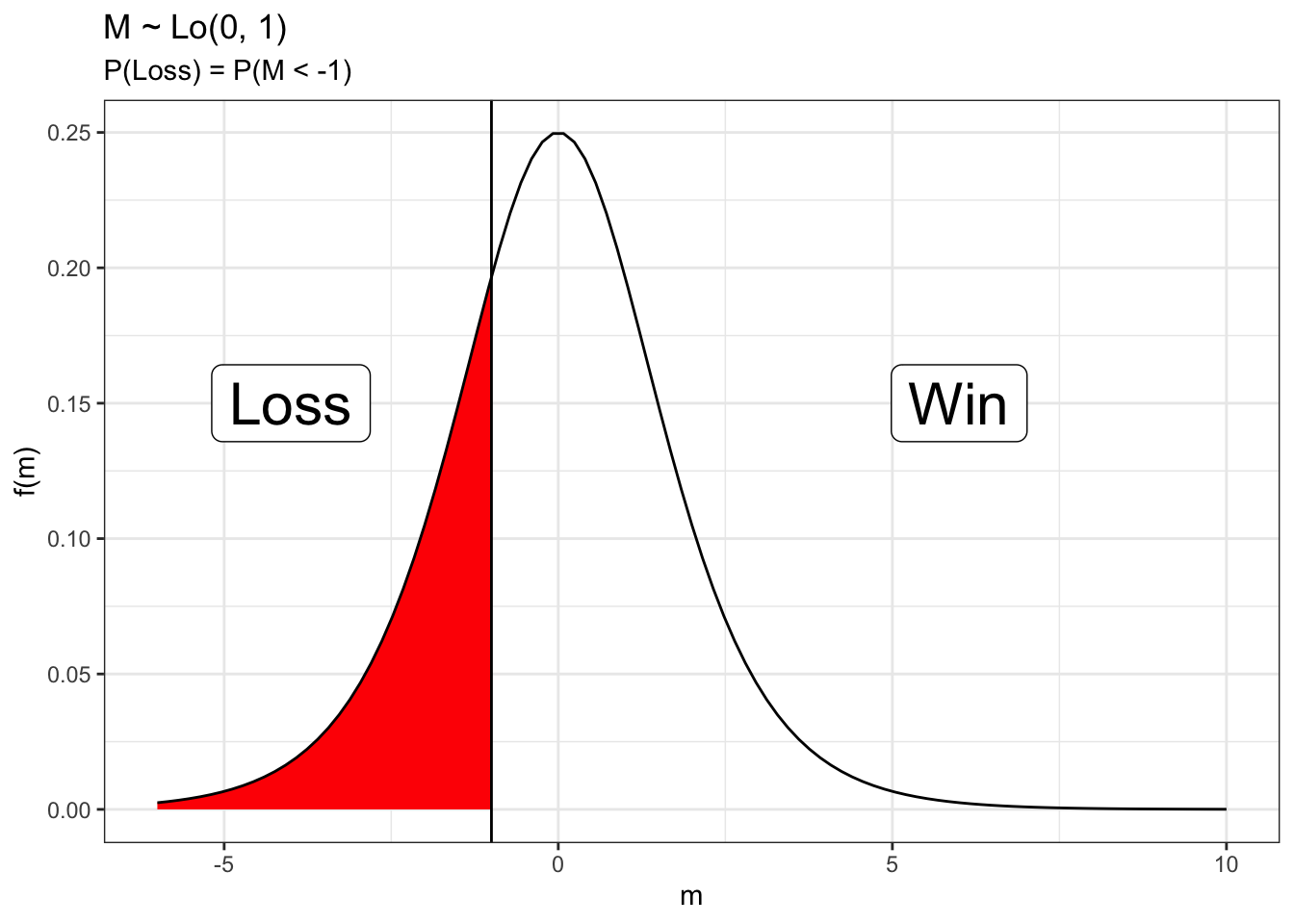
An equivalent way to express this model introduces a latent variable\(M_g^\zeta\) with a logistic distribution. Given this latent variable, the outcome is deterministic. Namely, \[H_g = \mathrm{I}(M_g^\zeta > 0)\] Latent variables often have a real-world interpretation. In this case, \(M_g^\zeta\) is related to the margin of victory. If the margin of victory is greater than 0, the home team wins and the home win indicator is 1, i.e. \(H_g = 1\).
In the implementation of the model used below, we will need a transformed version of this latent variable \(M_g = M_g^\zeta - \zeta\). With this transformed version we have
\[H_ g = \mathrm{I}(M_g > -\zeta)\] For logistic regression, \(M_g\) has a logistic distribution. For identifiability reasons, this distribution has a fixed scale parameter and, by convention, is often set to 1. Thus, \[M_g \stackrel{ind}{\sim} Lo(\mu_g, 1).\] The mean of this distribution is our typical model using home advantage and team strengths. \[\mu_g = E[M_g] = \theta_{H[g]} - \theta_{A[g]}.\] We can show \(\pi_g = P(M_g > -\zeta)\) and thus the latent variable representation is exactly the same as the typical representation we have used previously. Changing \(E[\mu_g]\) changes where the logistic distribution is centered on the number line and therefore the \(P(M_g > -\zeta)\).
In this figure, we can see that the estimated home advantage can be alternatively interpreted as the threshold (or cutpoint) for change from a loss to a win. Values for \(M_g\) below the threshold result in a loss while values above the threshold result in a win.
8.1.2 Ordinal Logistic Regression
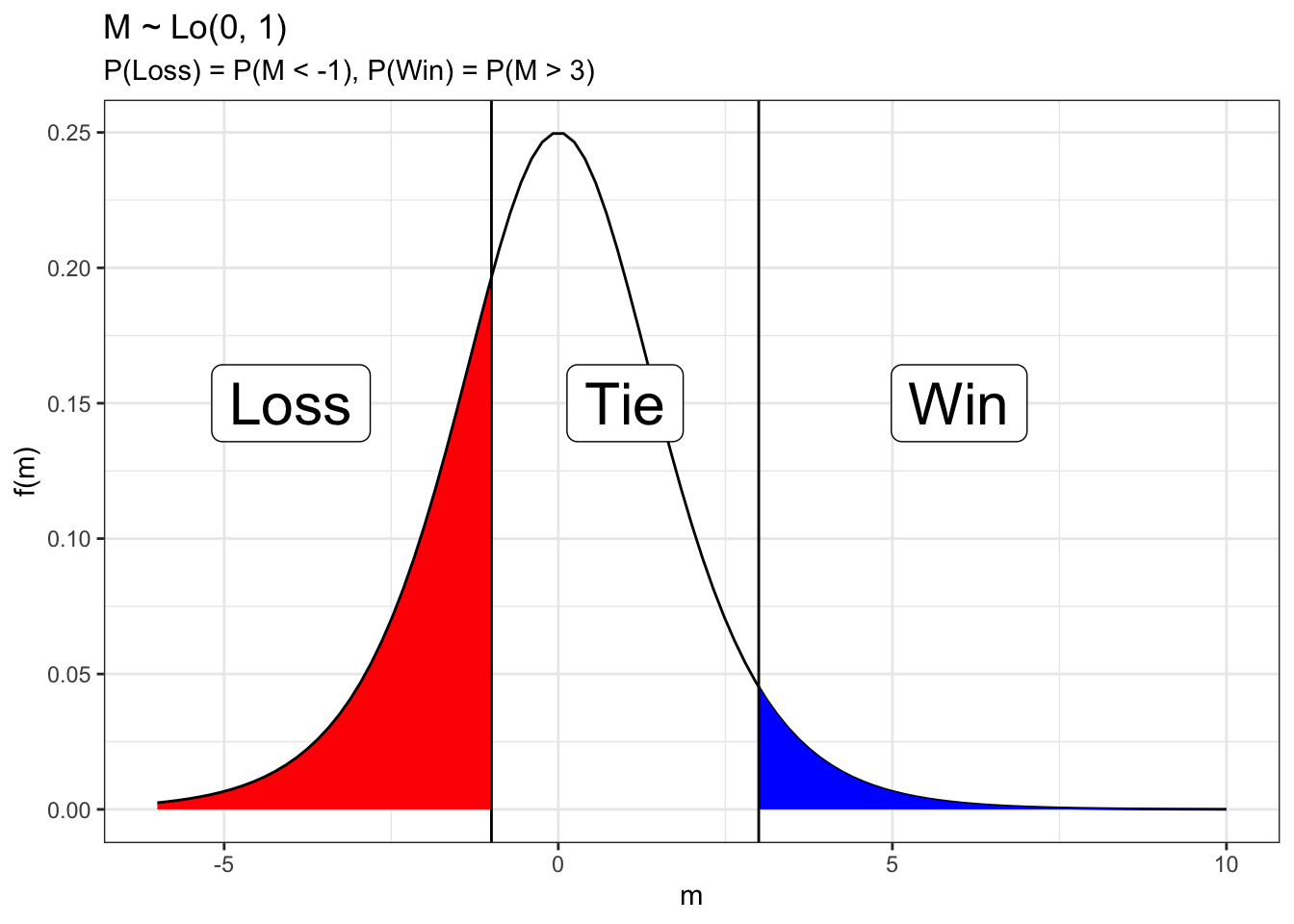
To account for ties in addition to wins and losses, we can include an additional threshold to separate ties from wins.
Modifying the above picture it may look something like this.
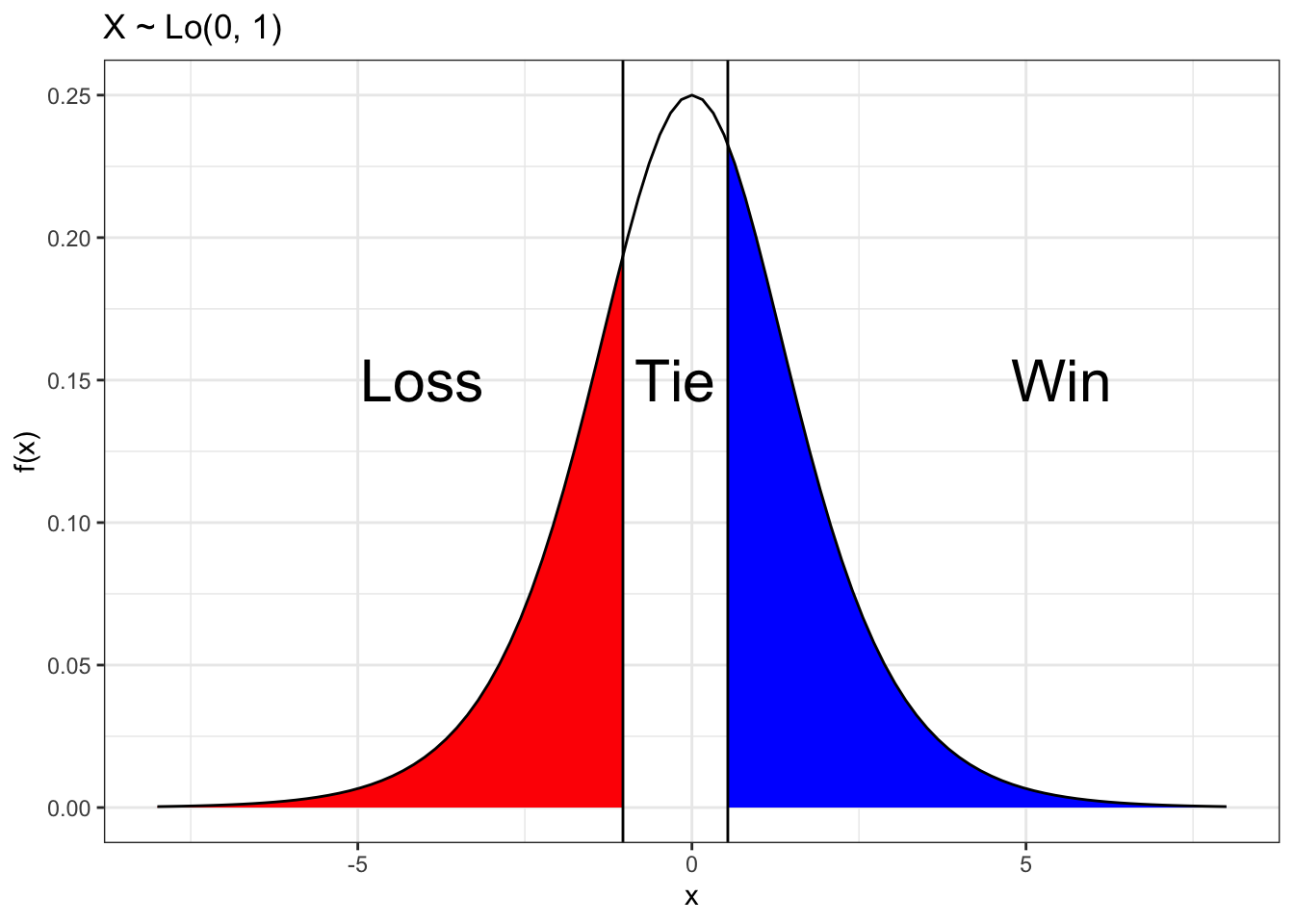
So we ordinal logistic regression model has a similar latent variable \[M_g \stackrel{ind}{\sim} Lo(\theta_{H[g]} - \theta_{A[g]}, 1)\] and two thresholds \[\mbox{R}_g = \left\{ \begin{array}{ll}
Loss & M_g < \zeta_1 \\
Tie & \zeta_1 < M_g < \zeta_2 \\
Win & \zeta_2 < M_g
\end{array} \right.\]\(R_g\) is an ordinal categorical variable that indicates the result of the game (loss, tie, or win) from the home team’s perspective. The parameters in this model are
\(\theta_t\): strength of team \(t\),
\(\zeta_1\): threshold separating loss from tie, and
\(\zeta_2\): threshold separating tie from win.
The thresholds are common to all games and teams. The thresholds are related to home advantage since, as the values of these thresholds get more negative, the probability the home team wins increases.
To calculate loss, tie, and win probabilities, we calculate the probability that the latent variable \(M_g\) falls within the three intervals: \((-\infty, \zeta_1)\), \((\zeta_1, \zeta_2)\), and \((\zeta_2,\infty)\), respectively.
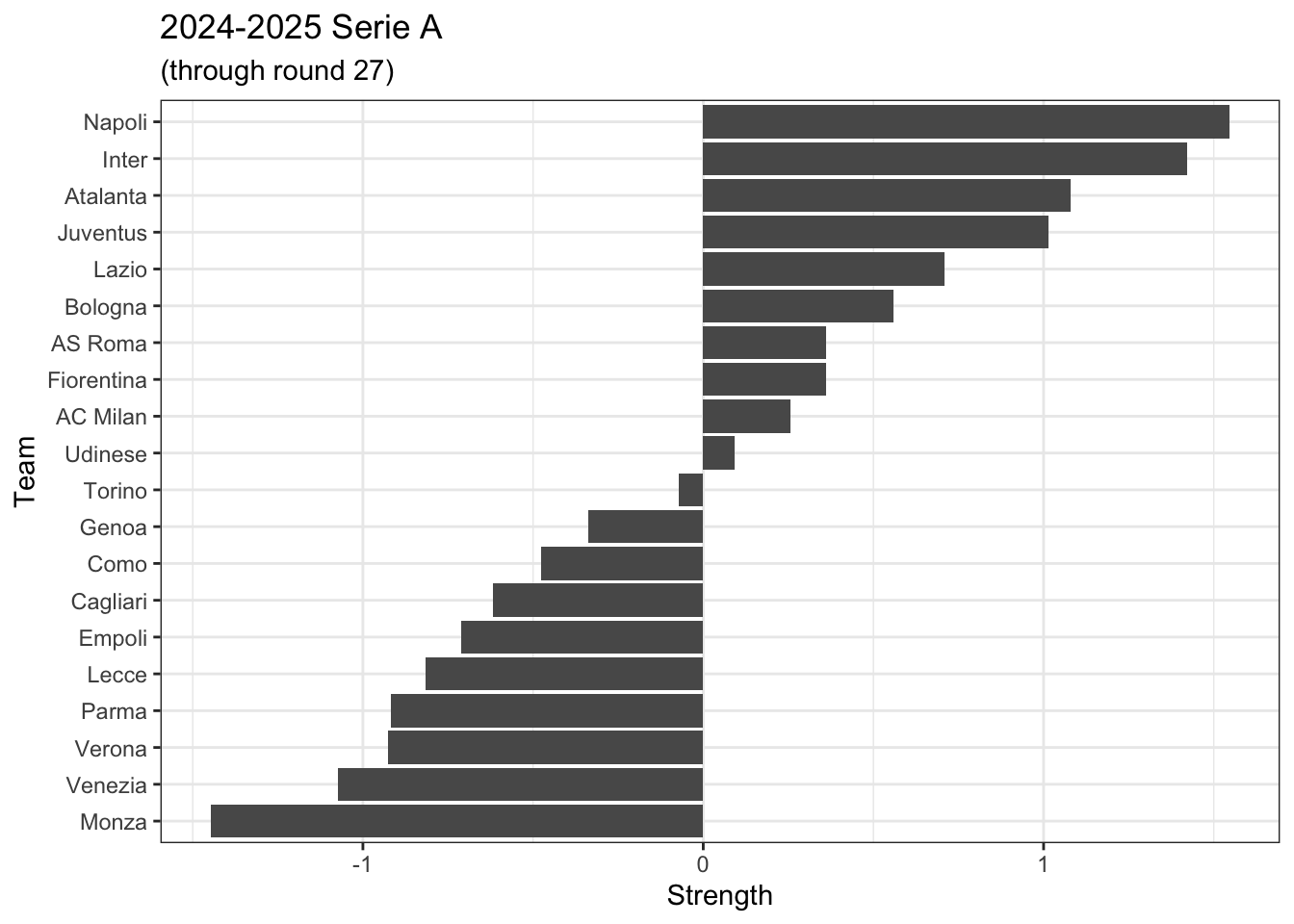
When we construct the ordered factor of loss-tie-win, we put it in order from loss to win. This results in team strengths where higher numbers indicate stronger teams.
An appealing aspect of this package is the ability to fixed mixed effect ordinal regression models using the clmm() function.
8.4 Summary
The development here used the logistic distribution due to its relationship with logistic regression. An alternatively commonly used approach uses the normal distribution due to its relationship with probit regression.