In this chapter, we investigate models when you only observe the binary outcome of the home team winning the game.
library("tidyverse"); theme_set(theme_bw())
Warning: package 'purrr' was built under R version 4.4.1
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4.9000 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.4
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library("DT")library("BradleyTerry2")
A simple example of margin-of-victory data is this fictitious collection of 4 teams that have played 5 games.
d <-tribble(~home, ~away, ~home_score, ~away_score, 1, 2, 21, 7,2, 3, 13, 14,4, 1, 3, 28,3, 4, 31, 0,1, 3, 42, 10) |>mutate(home_win = home_score > away_score # binary indicator of who won )
For the analysis that follows, we will construct a model matrix \(X\) where \(X_{g,t} = 1\) if team \(t\) is the home team in game \(g\), \(X_{g,t} = -1\) if team \(t\) is the away team in game \(g\), \(X_{g,t} = 0\) otherwise.
Similar to the margin-of-victory models, the individual \(\theta\)s are not identifiable, but only their difference is.
7.1.2 Graph connectednss
Just like the margin of victory models we will also have identifiability issues if the graph isn’t connected. If the graph is sparsely connected, as happens with conference play, then games that connect parts of the graph will have an outsized influence on the overall estimate of team strength.
7.1.3 Separation
An issue that exists in these models for binary outcome that doesn’t exist for the margin-of-victory models is the issue of separation.
Separation
A complete separation in a win-loss model occurs when one team has either won or lost all of their games.
If a team has won all of their games, then it is impossible to determine how good that team is. Thus their team strength can be arbitrarily large.
m <-glm(d$home_win ~ X, family =binomial(link ="logit"))
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
The warning in this output is an indication that separation has occurred.
summary(m)
Call:
glm(formula = d$home_win ~ X, family = binomial(link = "logit"))
Coefficients: (1 not defined because of singularities)
Estimate Std. Error z value Pr(>|z|)
(Intercept) 7.429 72844.703 0 1
X1 32.606 125856.238 0 1
X2 -14.266 153887.408 0 1
X3 16.709 95064.223 0 1
X4 NA NA NA NA
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 6.7301e+00 on 4 degrees of freedom
Residual deviance: 3.5615e-10 on 1 degrees of freedom
AIC: 8
Number of Fisher Scoring iterations: 23
The large standard errors are another indication that separation has occurred. Of course, it is best practice to make sure that every team has won and lost at least one game before you get to the step of fitting the model.
Separation can also be observed if the home team wins every game. In this situation, the home advantage parameter can be arbitrarily large.
Other separation situations can occur. For example, imagine that there are two conferences and, in every inter-conference game, one conference wins all the games. In this situation, we have no information about how much better one conference is than the other.
Separation is typical problem in logistic regression models, but particularly a problem in the types of models we are using for win-loss data.
7.1.4 Transivity
Similar to margin-of-victory models, this win-loss model is transitive: if Team A is better than Team B and Team B is better than Team C then Team A is better than Team C. That is, there is no information about specific matchups.
7.2 Rating Systems
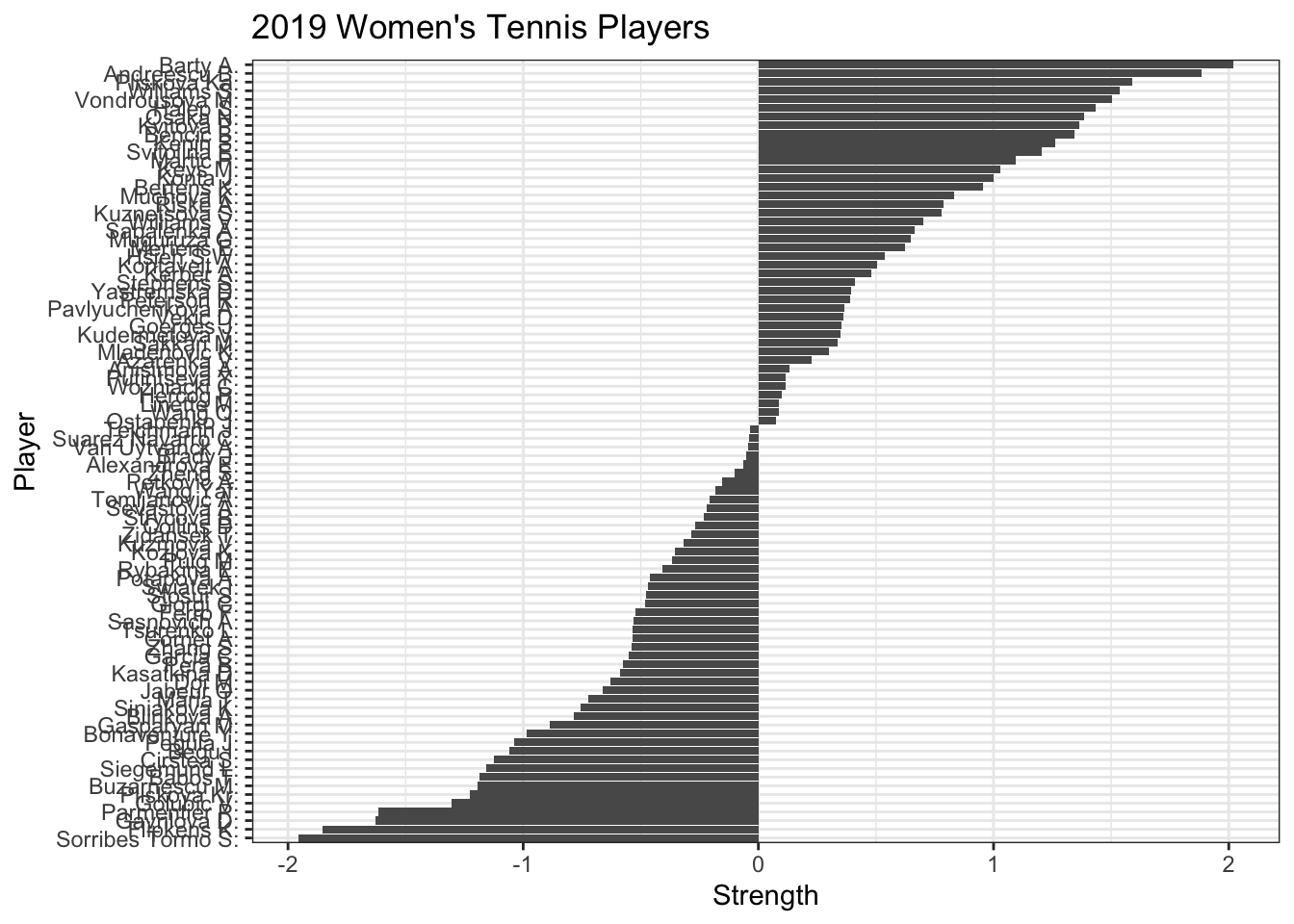
Anybody know of any purely win-loss ratings systems? Perhaps one of the tennis rating systems:
football <-read.csv("data/Iowa_High_School_Football_4A_Game_Scores_2018.csv") |>filter(Playoffs ==0) |># Not playoffsmutate(home_win = HomeScore > AwayScore )
Let’s take a look at the graph
library("networkD3")
Attaching package: 'networkD3'
The following object is masked from 'package:DT':
JS
p <-simpleNetwork(football, height="100px", width="100px", Source ="AwayTeam", Target ="HomeTeam", linkDistance =10, # distance between node. Increase this value to have more space between nodescharge =-900, # numeric value indicating either the strength of the node repulsion (negative value) or attraction (positive value)fontSize =14, # size of the node namesfontFamily ="serif", # font og node nameslinkColour ="#666", # colour of edges, MUST be a common colour for the whole graphnodeColour ="#69b3a2", # colour of nodes, MUST be a common colour for the whole graphopacity =0.9, # opacity of nodes. 0=transparent. 1=no transparencyzoom = T # Can you zoom on the figure? )p
Overall this graph looks reasonably connected.
# Proportion home winsfootball |>summarize(p =mean(home_win))
p
1 0.5284091
So we don’t have to worry about identifiability of the home-field advantage parameter.
I didn’t bother calculating statistics here because due to the small number of games each team played, there will definitely be some teams that have 0 wins and some that have 0 loses.
Limit the data to only individuals who have played at least 20 games. When we eliminate some games, the individuals remaining may have less than 20 games. The hope is that everybody has at least one win and one loss.
p <-simpleNetwork(tennis_filtered, height="100px", width="100px", Source ="Winner", Target ="Loser", linkDistance =10, # distance between node. Increase this value to have more space between nodescharge =-900, # numeric value indicating either the strength of the node repulsion (negative value) or attraction (positive value)fontSize =14, # size of the node namesfontFamily ="serif", # font og node nameslinkColour ="#666", # colour of edges, MUST be a common colour for the whole graphnodeColour ="#69b3a2", # colour of nodes, MUST be a common colour for the whole graphopacity =0.9, # opacity of nodes. 0=transparent. 1=no transparencyzoom = T # Can you zoom on the figure? )p
This graph looks complete and well connected. Perhaps this is unsurprising because the top tennis players play a lot of games against each other over the course of a year.
Finally, we can fit our logistic regression model. For these data, we do not have a binary column that indicates the winner. Instead, we have a column that indicates the winner by name. Thus, we will need to create a binary column that indicates the first column (named Winner) is the winner.
# Fit logistic regression model# since columns are Winner/Loser the result should always be TRUE,# i.e. the first column wonm <-glm(rep(TRUE, nrow(X_t)) ~ X_t -1, # no home fieldfamily =binomial(link ="logit")) tail(coef(m)) # includes last team as NA
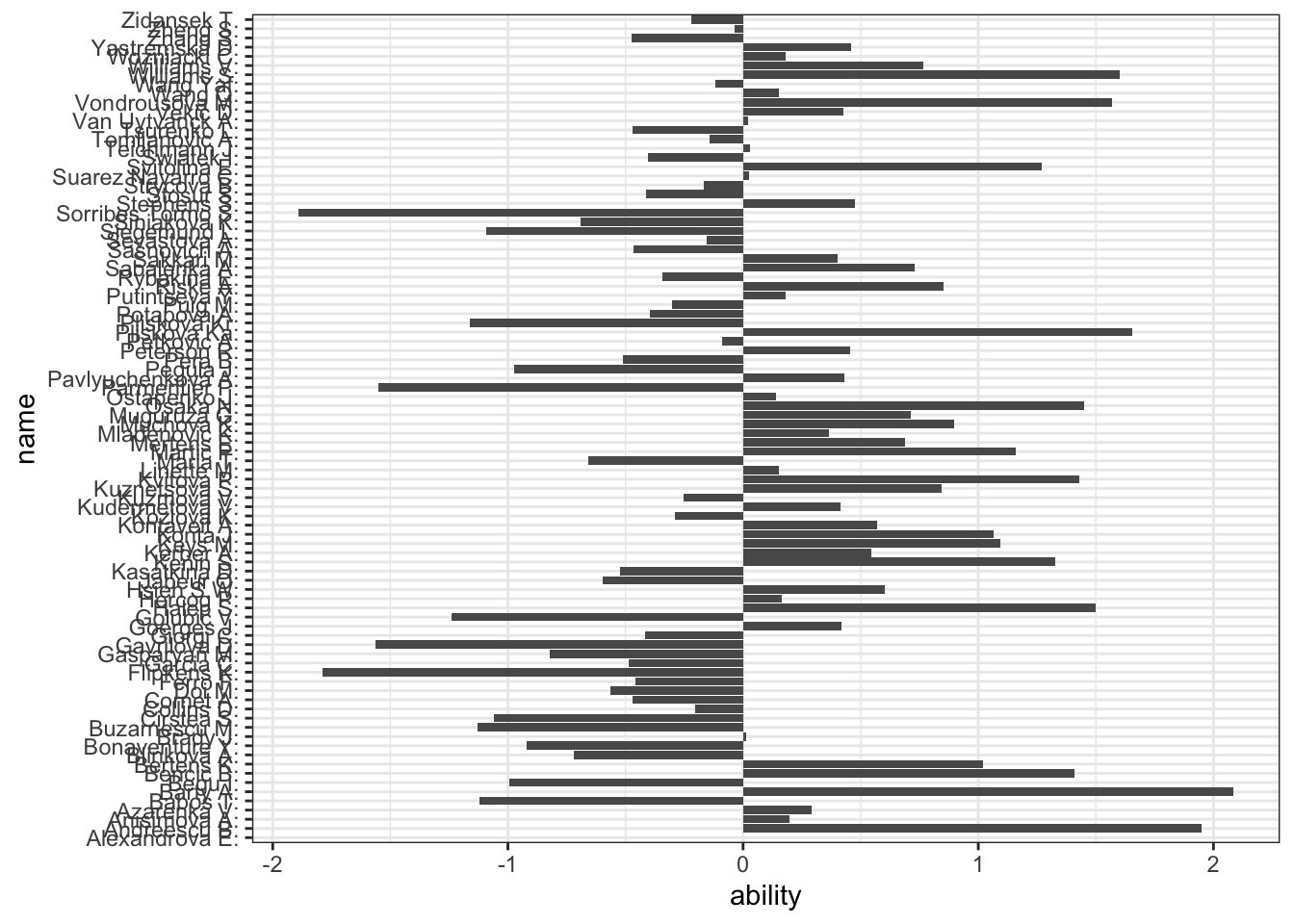
The models discussed in this chapter are often referred to as Bradley-Terry models after the 1952 Biometrika article written by Ralph Bradley and Milton Terry (Bradley and Terry 1952).
d <- BradleyTerry2::BTabilities(bt_m) |>as.data.frame()d$name <-rownames(d)ggplot(d,aes(x = ability,y = name )) +geom_bar(stat ="identity")
Bradley, Ralph Allan, and Milton E. Terry. 1952. “Rank Analysis of Incomplete Block Designs: I. The Method of Paired Comparisons.”Biometrika 39 (3/4): 324–45. http://www.jstor.org/stable/2334029.